
PianoVAE: VAE For Piano Notes Generation
A Pytorch Implementation of VAE-based musical model to generate and interpolate piano’notes using Nottingham dataset.
Table of Contents
- Introduction
- Nottingham’ Dataset
- Setup
- Run the code
- Training
- Inference
- Play with the model
- Acknowledgement
- Connect with me
- License
Introduction
This is a Pytorch implementation of a musical model that capable to generate piano’notes and interpolate between them as the model latent space is continuous. The model is a variational autoencoder where the encoder and the decoder are LSTM networks. The model is trained on Nottingham dataset, you can download it from here.

Nottingham’ Dataset
The Nottingham Music Database contains over 1000 Folk Tunes stored in a special text format. The dataset has been converted to a piano-roll format to be easily processed and visualised. Here is a sample from the dataset that you can listen to:
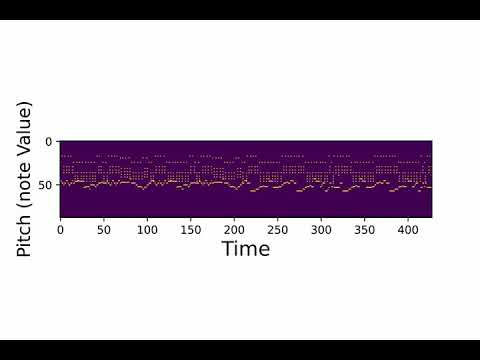
Setup
The code is using pipenv as a virtual environment and package manager. To run the code, all you need is to install the necessary dependencies. open the terminal and type:
git clone https://github.com/Khamies/Piano-VAE.gitcd Piano-VAEpipenv install
And you should be ready to go to play with code and build upon it!
Run the code
- To train the model, run:
python main.py - To train the model with specific arguments, run:
python main.py --batch_size=64. The following command-line arguments are available:- Batch size:
--batch_size - Learning rate:
--lr - Embedding size:
--embed_size - Hidden size:
--hidden_size - Latent size:
--latent_size
- Batch size:
Training
The model is trained on 20 epochs using Adam as an optimizer with a learning rate 0.001. Here are the results from training the LSTM-VAE model:
-
KL Loss

-
Reconstruction loss

-
KL loss vs Reconstruction loss

-
ELBO loss

Inference
1. Sample Generation
Here are generated samples from the model. We randomly sampled two latent codes z from standard Gaussian distribution. The following are the generated notes:
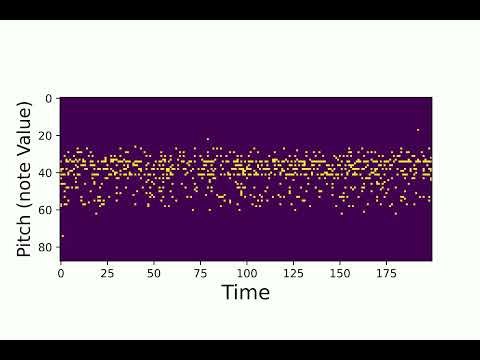
2. Interpolation
Here are some samples from the interpolation test. We use number of interpolation = 32, and sequence length = 200.
-
First audio:
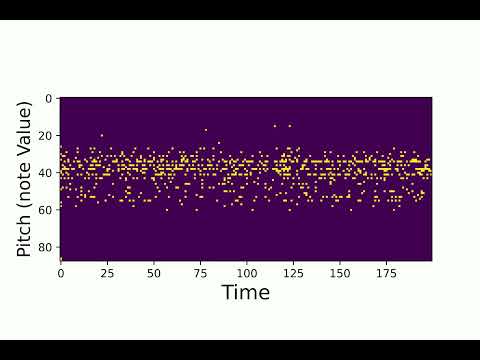
-
Second audio:
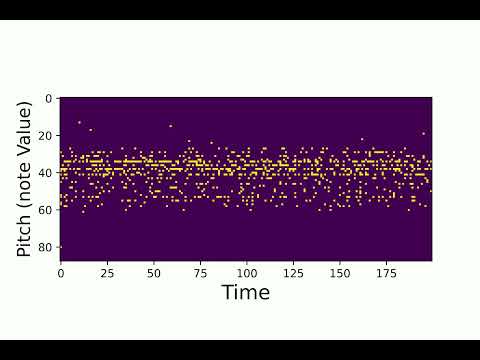
An interpolation close to “first audio”
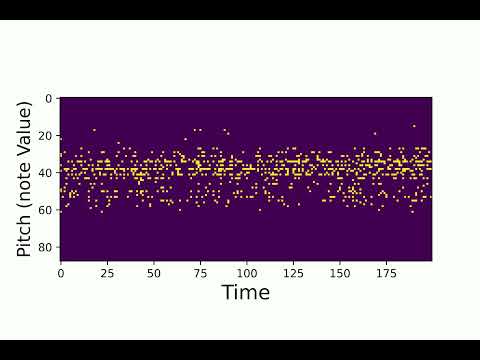
An interpolation close to “second audio”
Play with the model
To play with the model, a jupyter notebook has been provided, you can find it here
Acknowledgement
- Big thanks to @montaserFath for reviewing the code!
Citation
@misc{Khamies2021Piano-VAE,
author = {Khamies, Waleed},
title = {A Pytorch Implementation of VAE-based musical model to generate and interpolate piano'notes using Nottingham dataset.},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/Khamies/Piano-VAE}},
}
